Reduce your time to insight—without compromising
Patent data holds a wealth of information about technology trends, competitive activity, and emerging opportunities and threats, but getting the right insights from patent data can be a notoriously challenging task.
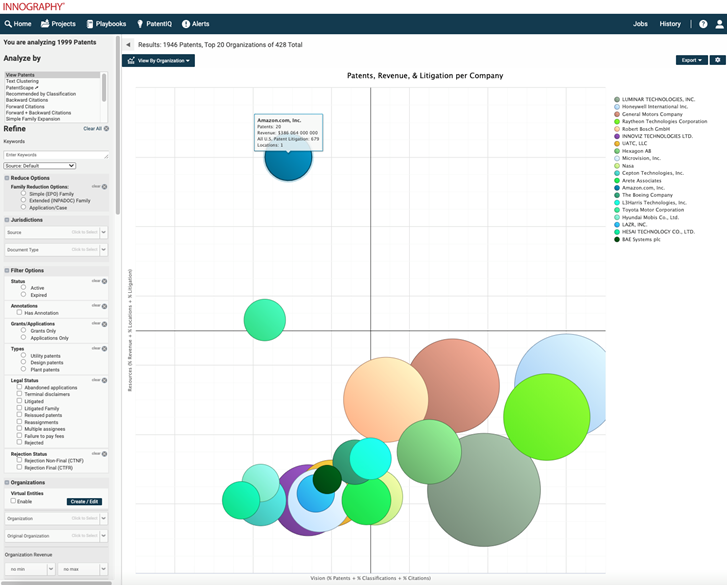
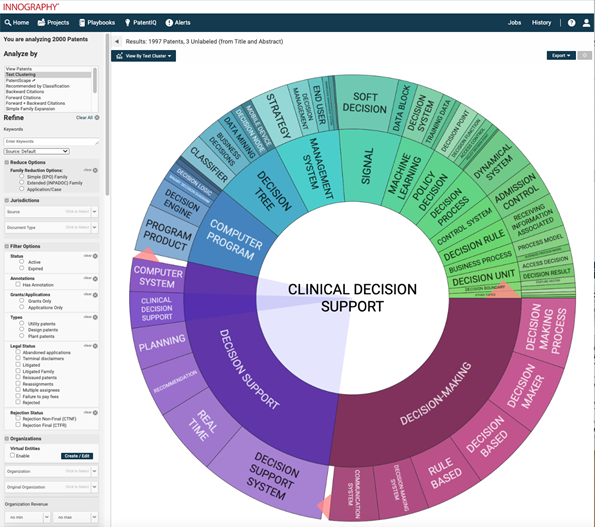
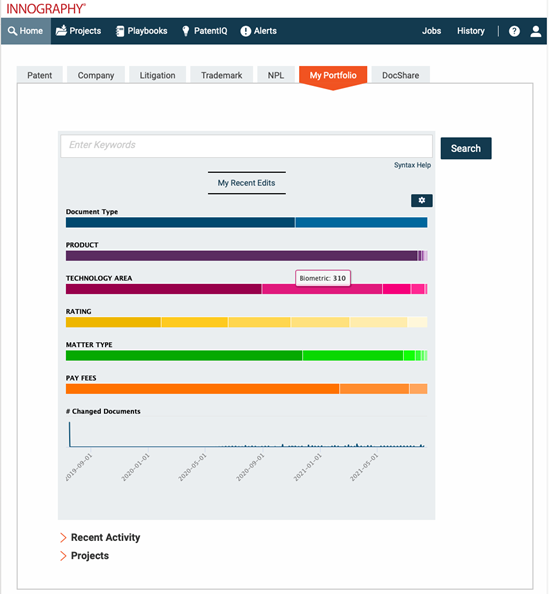
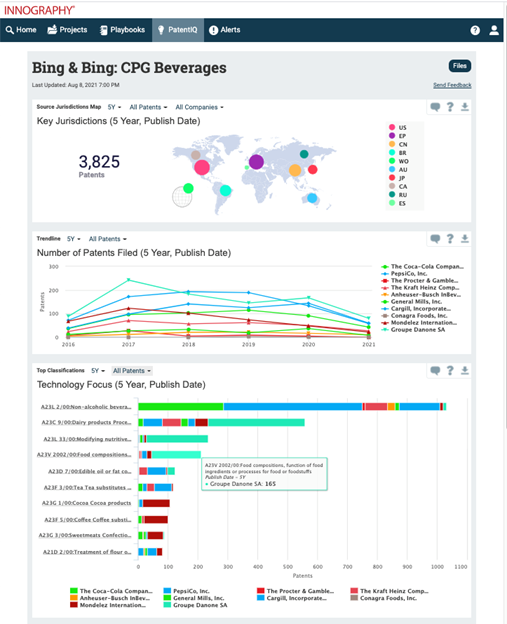
By correlating patent data with firmographic, litigation and patent valuation data, and providing powerful, yet easy-to-use AI-powered search and analytics tools, Innography helps R&D, strategy, M&A and licensing teams capture the right insights with speed and confidence.